Enterprise Hosting Backup and Disaster Recovery

Table of Contents

Enterprise hosting backup and disaster recovery defines the operational architecture that enables an enterprise website to maintain digital continuity, recover from infrastructure failures, and meet declared targets for uptime, retention, and performance. It is the infrastructure responsible for delivering high availability with system-wide uptime targets of 99.99%, recovery point objectives (RPO) of five minutes or less, and recovery time objectives (RTO) of one hour or less across geo-distributed hosting regions.
An enterprise website operates on an infrastructure that must support continuous uptime, real-time data consistency, and rapid fault resolution. This operational continuity is sustained by a disaster recovery system that replicates stateful data, automates failover processes, and verifies restore sequences through scheduled validation cycles. From content delivery networks and CMS platforms to dynamic user sessions and transactional services, every digital layer is subject to this recovery logic.
A solid backup strategy includes cross-regional replication, tiered storage models, and the retention of immutable snapshots. It ensures system integrity not by storing isolated data files, but by preserving the full operational state, encompassing application configurations, databases, service dependencies, and active user contexts. These elements are replicated and restored through orchestrated workflows designed to bring the enterprise website back online without data loss or compliance violations.
Automation pipelines govern these workflows at scale. They manage snapshot scheduling, detect failure conditions, execute recovery processes, and enforce service-level compliance across large-scale architectures. Automation in this context is not a matter of operational efficiency; it is a system-enforced mechanism for ensuring correctness, resilience, and traceability across dynamic infrastructure layers under stress.
Compliance standards such as ISO/IEC 27001, SOC 2, HIPAA, and GDPR evaluate the design and effectiveness of backup and disaster recovery systems in regulated environments. In such contexts, disaster recovery is a legally required system function. It must enforce data residency requirements, preserve immutable audit logs, and demonstrate recovery capabilities through documented testing. The enterprise website, as a regulated digital asset, is obligated to operate within these compliance-driven architectural boundaries.
Disaster Recovery Architecture
Disaster recovery architecture defines how enterprise infrastructure behaves under failure conditions, coordinating the mechanisms that sustain continuity, minimize latency, and preserve service fidelity across all layers of the hosting stack.
This architecture distributes compute, storage, and network resources in a way that enables redundancy and fault tolerance. It designs failover pathways and replication models to uphold service integrity and support compliance with uptime SLAs.
Enterprise hosting environments typically adopt either active-active or active-passive configurations:
- In active-active setups, live application state is mirrored across high-availability clusters and multi-zone deployments, allowing for real-time traffic routing and seamless failover.
- Active-passive architectures maintain a standby infrastructure, which is activated only when health checks detect a failure.
Each model operates within specific RPO (Recovery Point Objectives) and RTO (Recovery Time Objective) thresholds, balancing tradeoffs among latency, complexity, and cost.
At the core of recovery orchestration lies data replication:
- Synchronous replication ensures transactional consistency by requiring all writes to be acknowledged across nodes before commit, offering near-zero RPO at the expense of increased cross-region latency.
- Asynchronous replication, by contrast, reduces latency but may permit minor data loss during rapid transitions.
The choice between these models aligns with the application’s recovery strategy, where stateful services require checkpoint coordination and stateless services allow for greater distribution flexibility.
Automated failover is implemented through infrastructure-as-code (IaC), embedding health checks, traffic distribution logic, and storage validation within declarative orchestration layers. These mechanisms do more than recover services; they isolate faults, replicate configurations, and verify readiness within seconds. Virtual machine transitions, DNS rerouting, and container orchestration are executed via logic flows designed to eliminate manual intervention and ensure sub-minute recovery times.
Hot, Cold, and Warm Site Models
Disaster recovery infrastructure is commonly categorized into hot, warm, and cold site models, each reflecting a deliberate tradeoff between recovery speed, operational cost, and resource allocation. These models define how an enterprise website restores functionality after a disaster event, directly impacting RTO/RPO targets, service continuity, and end-user experience.
A hot site maintains a fully mirrored replica of the primary hosting environment in a secondary region. This setup includes synchronized databases, live application servers, and active load balancers, all configured in real-time operational states. Continuous data mirroring supports sub-60-second failovers without manual intervention. Hot sites are triggered automatically by health check failures or regional outages, offering the fastest recovery times at the highest cost and with the most complex infrastructure.
A warm site provides a partially active environment with pre-provisioned resources and deferred activation mechanisms. Data synchronization occurs at scheduled intervals, such as hourly, while application instances remain paused or in a boot-ready state. Recovery involves DNS failover, resource provisioning, and rehydration of configuration. Failover completion typically occurs within 1–4 hours, making warm sites ideal for systems with moderate uptime requirements and non-critical transaction loads.
A cold site consists of offline storage for backups, configurations, and system images, without active compute or network infrastructure. Upon disaster detection, the whole environment must be instantiated, including disk recovery, instance creation, application redeployment, and credential restoration. Cold site activation spans 4 to 48 hours, best suited for archival platforms, internal tools, or low-priority services with relaxed recovery timelines.
Recovery Time Objectives (RTO)
A Recovery Time Objective (RTO) defines the maximum acceptable duration that a system, including its applications and infrastructure, can remain unavailable before it causes intolerable disruption to business operations. RTO is not a theoretical metric; it is a strictly enforced SLA constraint that governs how quickly services must be restored following an outage. For enterprise websites, RTO directly shapes architecture, cost structures, and the strategic configuration of disaster recovery systems.
The availability of an enterprise website is architecturally constrained by its defined RTO. Whether the platform handles high-volume transactions, sensitive data flows, or customer-facing functionality, the allowable downtime is determined by the business criticality and user tolerance of the system. Tier-1 applications may require recovery within five minutes, necessitating high-availability architectures with fully redundant resources and pre-warmed instances. Conversely, a non-essential internal portal may tolerate a 1–4 hour RTO, supported by warm-site infrastructure and deferred activation routines.
Disaster recovery systems are engineered to meet specific RTO targets. Hot-site architectures, real-time replication, and automated provisioning scripts are in place to compress recovery timelines and meet business continuity requirements. When a disruption occurs, failover workflows are triggered by monitoring systems that comprise the observability layer. These systems detect failure, initiate resource scaling, restore system states, and drive full-stack recovery within SLA-defined timeframes.
Hosting providers must offer capabilities aligned with the enterprise’s recovery timeline. This includes infrastructure that supports sub-minute VM instantiation, rapid DNS propagation, and multi-zone state restoration. Providers unable to deliver RTO-compliant architectures effectively disqualify themselves from enterprise contracts that enforce stringent uptime guarantees.
Recovery Point Objectives (RPO)
A Recovery Point Objective (RPO) defines the maximum allowable time between the last successful data capture and the onset of a system disruption. It sets a hard limit on tolerable data loss and directly informs how often backups and replication events must occur to protect enterprise website operations. It is an operational threshold that enforces data durability, transactional consistency, and rollback viability.
Backup systems are designed to capture data at intervals aligned with specified RPO targets. For instance, hourly snapshots establish a 60-minute RPO, whereas continuous data mirroring supports sub-minute recovery with minimal data loss. These protection strategies are governed by the disaster recovery architecture, which implements mechanisms such as log shipping, synchronous/asynchronous replication, and snapshot-tiered storage to match business risk tolerances.
Enterprise websites often operate across diverse data domains, from high-frequency transaction logs to low-volatility CMS content. Each domain carries a distinct rollback tolerance. An e-commerce checkout process, for example, may demand RPOs under five minutes, while static blog content may safely accommodate hourly backups. Application-layer data must be synchronized with precision, especially when legal liabilities or compliance regulations penalize excessive data gaps.
To maintain RPO compliance, data systems rely on methods such as write-ahead logging, real-time replication across fault zones, and tiered storage architectures. Storage layers (including hot, warm, and archival tiers) determine the speed at which data can be restored to a valid state within the required consistency window.
Importantly, short RPOs are not inherently superior. Assigning a 5-minute RPO to static media assets may increase infrastructure costs without enhancing business value. RPO targets must reflect data volatility, regulatory exposure, and operational priorities. Striking the right balance between backup frequency and infrastructure efficiency ensures that data protection remains both scalable and cost-effective.
Backup Frequency Models
Backup frequency models define the timing cadence at which system states are captured, synchronized, and stored within enterprise hosting environments. These models (whether real-time, hourly, daily, or weekly) are more than operational schedules. They are structural parameters that shape data preservation strategies, infrastructure load, and recovery responsiveness. Frequency decisions are engineered to align with RPO targets, data volatility, and application-level sensitivity across the enterprise website.
Real-time backup models support continuous data protection (CDP), capturing every change as it happens. This approach is essential for high-risk systems, such as e-commerce checkouts, payment gateways, and real-time analytics platforms, where even a few milliseconds of rollback can introduce unacceptable risk. While CDP enables near-zero data loss, it places heavy demands on storage I/O, replication engines, and write buffering layers.
Hourly backup models rely on snapshot orchestration and are often used for dynamic but non-transactional systems, such as CMS databases, session storage, or CRM platforms. These backups typically occur at intervals ranging from 15 to 60 minutes, offering a balance between data freshness and infrastructure sustainability. Content-driven enterprise websites, particularly those with high publishing frequencies, rely on this model to maintain session fidelity and editorial continuity.
Daily backup models function as scheduled full-system captures, often executed during off-peak windows (e.g., 2:00 AM daily). This model supports rollback tolerances of up to 24 hours and is best suited for semi-static systems such as logging platforms, legal archives, or internal reporting environments. It reduces bandwidth load and storage churn but increases potential data exposure during failure events.
Weekly or event-driven backup models apply to archival data, regulatory logs, and version-controlled environments. These backups are triggered by key events such as software releases, month-end reports, or compliance checkpoints. The model reduces infrastructure strain and extends the data retention horizon, making it suitable for systems with low volatility and RPO tolerances of 72 hours or more.
Full, Incremental, Differential
Backup types define the data capture methodology within the enterprise disaster recovery architecture. Full, Incremental, and Differential backups represent system-scoped strategies that determine what data is preserved, how restoration is sequenced, and what dependencies exist in the recovery process. Each type plays a distinct role in the multi-layered protection strategy supporting the enterprise website’s data layer, directly shaped by RPO/RTO thresholds, restore time requirements, and infrastructure limitations.
A full backup captures the entire system state, including application files, databases, and configuration settings, at a single point in time. It creates a comprehensive snapshot that enables complete restoration without requiring prior backups. This model offers maximum recovery reliability but demands high I/O throughput and extended execution times. Backup engines typically schedule full backups at lower frequencies (e.g., weekly) to reduce bandwidth strain and prevent storage saturation, particularly when multiple backup generations are retained.
An incremental backup captures only the data that has changed since the most recent full backup. This method significantly reduces storage consumption and speeds up the backup process, making it ideal for high-change environments such as CMS platforms or collaborative content systems. However, restoration requires the entire sequence of backups to be present and intact. If any link in the chain is missing or corrupted, recovery may fail. The backup orchestration system must rigorously track restore points and manage dependency chains to preserve recoverability.
A differential backup captures all changes made since the last full backup, regardless of any previous differentials. It offers a tradeoff between performance and reliability: while each backup grows larger over time, restoration requires only the last full backup and the most recent differential. This simplifies recovery workflows and reduces risk compared to incremental chains, while still offering better efficiency than daily full backups. Differential models are often used for systems with moderate change rates, such as CRM databases or employee portals, where faster restoration is prioritized but resource optimization remains essential.
Backup Storage Architectures
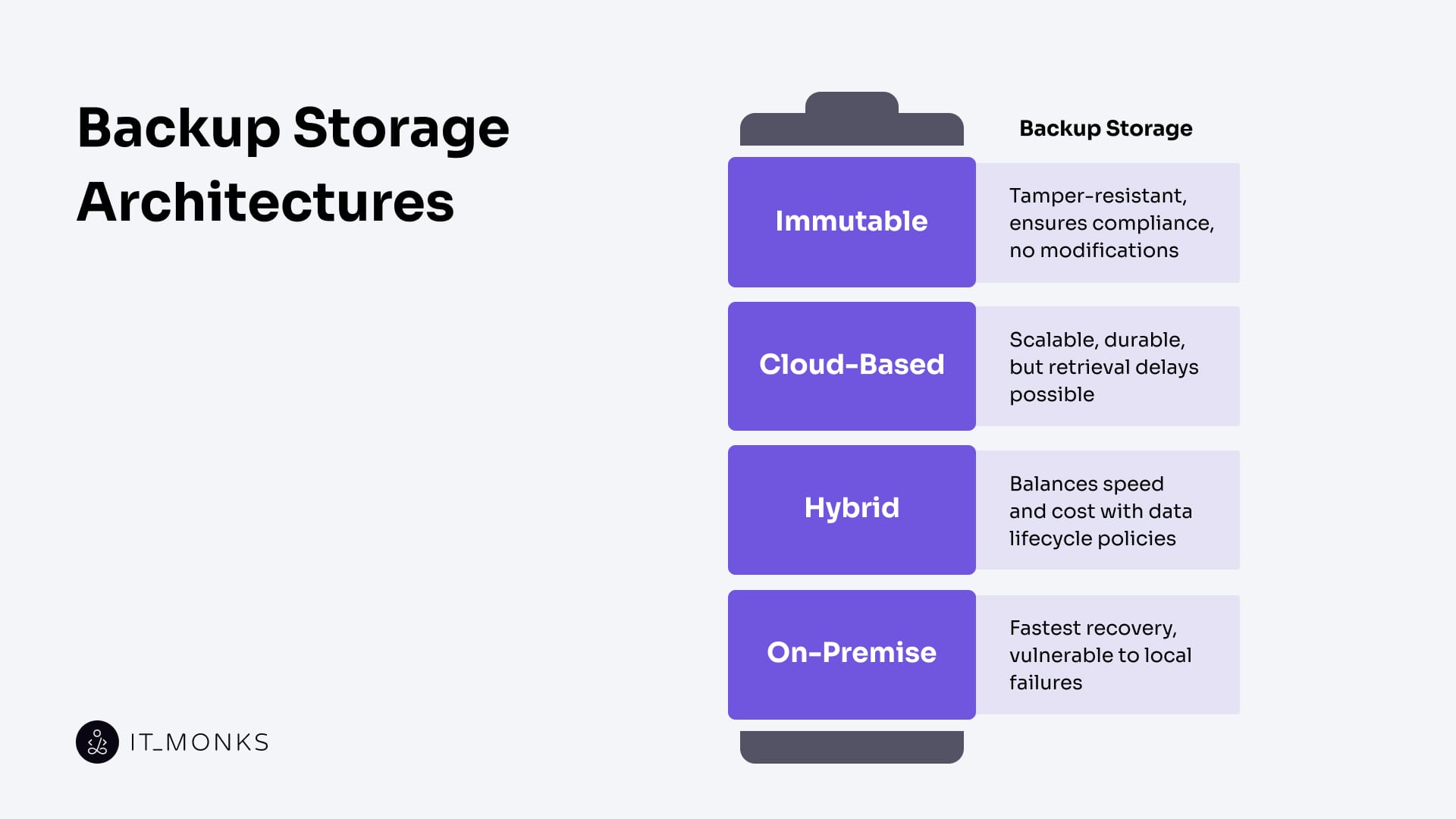
Backup storage architecture defines how disaster recovery data is retained, replicated, and restored across policy-driven, multi-layered systems. It is not a single endpoint but a dynamic composition of storage classes, each optimized for durability, access latency, and recovery throughput. From compliance-grade immutability to cost-efficient cloud tiering, storage design decisions directly shape backup integrity and determine whether RTO/RPO targets can be met.
Local storage architectures, such as on-premises NAS or SAN arrays, provide high-speed access to recent snapshots and short-cycle deltas. These systems support sub-minute recovery windows, making them ideal for Tier-1 hot storage in high-throughput environments. However, they lack geo-redundancy and are vulnerable to localized failures, which limits their role in broader disaster recovery strategies.
Cloud-based object storage architectures scale elastically and replicate data asynchronously across geographically distributed zones. Platforms like AWS S3 or Azure Blob Storage offer multiple retention classes (from frequent access to archival storage), each with distinct cost and latency profiles. For the enterprise website’s data layer, these services provide limitless backup capacity and built-in durability. However, cold storage tiers, such as S3 Glacier or Deep Archive, introduce retrieval delays and higher egress costs.
Hybrid storage architectures combine the immediacy of on-premise disks with the longevity of cloud-based archives. These systems implement hot/cold zoning and use data lifecycle policies to automate snapshot migration based on age, access frequency, and compliance category. This approach is well-suited for enterprise websites that blend real-time workloads (e.g., user sessions) with long-cycle data (e.g., monthly reports or analytics exports), optimizing both cost and performance.
Immutable storage layers, configured as WORM-enabled repositories, enforce unalterable retention policies in accordance with regulatory mandates such as HIPAA, SEC 17a-4, or GDPR. Once data is written, it cannot be modified or deleted, ensuring tamper-resistant backups for sensitive content, such as audit trails, legal documents, or user-submitted data. These storage blocks are crucial for demonstrating compliance and maintaining evidentiary integrity.
Validation and Testing Processes
Validation and testing ensure that backup datasets are not only captured correctly but can be reliably restored under real or simulated fault conditions. The validation process confirms that each backup is complete, uncorrupted, and capable of producing a viable recovery state. In parallel, structured testing workflows simulate restore procedures, auditing recovery performance, fault tolerance, and adherence to compliance across the enterprise disaster recovery system.
Backup systems initiate automated recovery simulations via orchestration workflows, executing non-disruptive failover tests in isolated sandbox environments. Each sequence begins with snapshot verification, proceeds through application-layer restoration, and concludes with detailed outcome logging. Test results are benchmarked against Recovery Time Objective (RTO) and Recovery Point Objective (RPO) thresholds, including metrics such as time-to-restore, rollback fidelity, and session state integrity.
Simulations are designed to emulate real-world failures under operational load. For example, a recovery drill might simulate the loss of a CMS database and assess whether restoration meets a 5-minute SLA threshold. These tests are typically run on a daily or scheduled basis, with results archived in audit logs required by compliance frameworks such as ISO 27001, SOC 2, and GDPR. SLA monitors flag anomalies (including replication delays, corrupted delta chains, or missing snapshots) for immediate remediation.
Backup integrity is further validated using checksum comparisons, manifest consistency checks, and version tracking. Immutable snapshots are mounted in read-only mode to verify the tamper-resistance of WORM (write-once-read-many) configurations. Across storage systems, databases, and CDNs, validation checkpoints confirm that restoration processes are not only functional but also demonstrably repeatable under regulatory scrutiny.
The disaster recovery posture of an enterprise website depends on these continuous validations. Without verified backups and rehearsed recovery workflows, uptime guarantees become assumptions rather than certainties. Automated testing (including cross-region failover drills, rollback audits, and user session restorations) is not a maintenance task. They are foundational architectural requirements that sustain business continuity KPIs and establish operational trust.
Compliance Requirements
Compliance requirements dictate how enterprise disaster recovery systems must retain, protect, and restore data within regulated operational boundaries. These mandates shape architectural decisions (including retention policies, data residency constraints, and recovery time obligations), particularly for enterprise websites managing financial transactions, personal data, or industry-regulated content. Whether imposed by GDPR, HIPAA, SOX, or PCI-DSS, such standards elevate system configuration into a legally enforceable framework.
Backup strategies must adhere to jurisdiction-specific retention rules. For example, SOX mandates seven-year minimum record retention, while SOC 2 requires 90-day log preservation. These timelines are embedded directly into snapshot expiration policies, object lifecycle configurations, and cold storage tier assignments.
Storage systems enforce data immutability through WORM object locks, append-only block configurations, and non-rewritable archive tiers. These controls are essential for maintaining audit integrity, ensuring fraud resistance, and meeting legal obligations in sectors such as finance and healthcare. Tamper-proof data formats align with both legal integrity requirements and security standards in enterprise hosting, including zero-trust access and encryption enforcement.
Disaster recovery performance must comply with time-bound metrics defined by standards like ISO 27001. For instance, Tier-1 services may be required to demonstrate recovery within 4 hours (RTO) and limit data loss to under 15 minutes (RPO).
Access controls reinforce data security by restricting restore actions via role-based permissions, logging all access attempts, and applying end-to-end encryption policies. Backup vaults and restoration APIs are monitored through compliance-aligned audit layers, ensuring that each administrative action is traceable and adheres to policy.
Enterprise websites operate under rigorous compliance-driven infrastructure mandates, where every architectural element (from cloud region selection to backup frequency) must reflect mapped regulatory conditions. Non-compliance isn’t a technical risk; it is a structural liability. Encryption protocols, failover scheduling, snapshot retention, and geographic zoning are legal obligations enforced through system architecture.
Automation Workflows
Automation workflows enforce disaster recovery operations by translating high-level system policies into time-bound, event-driven execution chains. These workflows replace manual intervention with programmable infrastructure logic that responds to system state changes, such as heartbeat failures, snapshot expirations, or SLA violations. In enterprise hosting, automation is not an optional convenience layer; it is the backbone of operational continuity under pressure.
The recovery orchestration engine executes scheduled tasks, including nightly snapshots, weekly restore simulations, and continuous SLA compliance checks. These operations are pre-scripted using configuration-as-code, ensuring disaster recovery policies are version-controlled, auditable, and redeployable without human oversight. For instance, a snapshot scheduler may create incremental backups every four hours and trigger validation jobs upon each completion, thereby maintaining snapshot consistency across the storage tier.
Real-time monitoring systems trigger events that launch recovery workflows. These triggers may detect CPU degradation, disk I/O failures, or regional unavailability. Upon fault detection, the multi-region orchestration logic invokes predefined disaster recovery playbooks, re-routing traffic to hot standby sites or initiating cross-region data restoration. This automation framework ensures that enterprise websites maintain service availability and data integrity, even during incident windows or operational team downtime.
SLA monitoring systems enhance this by detecting performance breaches and activating corrective workflows. When a defined latency threshold is breached, the automation layer logs the event, verifies system health, and initiates restoration from the most recent snapshot within the allowable RPO window. These cascaded logic flows uphold service-level guarantees and generate audit-ready logs for regulatory compliance.
Compliance validators track each automated process, from snapshot generation to full-system recovery testing, ensuring alignment with documented disaster recovery policies. Timestamps, execution outcomes, and recovery durations are recorded and cross-referenced against SLA benchmarks, forming immutable and verifiable logs that are essential for audits under ISO 27001, SOC 2, and GDPR frameworks.
Enterprise hosting infrastructure relies on orchestration models that directly sustain both resilience and scalability through automation workflows. By eliminating human latency, these systems dynamically provision capacity, restore critical data, and validate system health in real time, ensuring that scale is achieved through robustness, not as a source of fragility.
Provider Capabilities
Provider capabilities define the operational boundaries of disaster recovery architecture within enterprise hosting environments. These are SLA-enforced foundational capabilities that determine how backup, failover, replication, and validation are executed under architectural and regulatory constraints. Each capability either enables or limits the enterprise’s ability to meet RTO/RPO targets, comply with governance frameworks, and scale infrastructure predictably.
Backup orchestration services must support full and incremental snapshot lifecycles with programmable scheduling, tiered storage integration, and API accessibility. The provider’s orchestration layer should accommodate diverse backup frequency models aligned to system criticality, such as hourly snapshots for transactional workloads and daily differentials for content platforms. These services ensure restore point availability, enforcing both temporal compliance and application consistency within the disaster recovery workflow.
Failover support systems must enable automated provisioning of hot or warm standby environments across multiple geographic zones. Triggered by real-time health checks or latency violations, these systems execute DNS re-routing, container redeployments, and storage remounts without manual intervention. The reliability of these mechanisms is measured by their ability to sustain availability zones and enforce geo-redundant recovery guarantees, which are critical for enterprise websites where downtime translates to direct revenue loss.
SLA monitoring and enforcement mechanisms expose observability endpoints and telemetry feeds that track RTO/RPO compliance in real time. These systems continuously evaluate latency, system responsiveness, and recovery job duration, triggering alerts or automated rerouting when thresholds are breached. A provider’s capability to monitor and enforce SLAs is essential for supporting high-tier workloads, including transactional systems, content delivery platforms, and session-preserving applications.
Data protection capabilities include snapshot immutability, configurable retention policies, and audit-compliant access logging. Providers must offer WORM-enforced storage layers and generate detailed logs across backup and restore operations. These features are required to meet regulatory obligations under GDPR, HIPAA, SOC 2, and similar frameworks. This is where SLA enforcement intersects with legal mandates on data retention, deletion, and access control.
Automation execution interfaces, such as webhook triggers, configuration-as-code bindings, and orchestration APIs, determine whether disaster recovery processes can execute without manual involvement. These interfaces must support automated snapshot scheduling, event-driven failover, orchestrated restores, and the generation of compliance reports. Enterprise-scale hosting environments depend on these integrations to maintain deterministic, traceable, and repeatable recovery logic.
Cost Modeling
Cost modeling defines the financial profile of disaster recovery infrastructure based on how architectural decisions translate into recurring and event-driven expenses. It does not rely on static vendor pricing tiers. Instead, it derives cost as a function of system behavior, including backup frequency, replication scope, restore patterns, automation cycles, and compliance enforcement. Every architectural decision directly influences the financial load and must be forecast with precision.
Backup configurations determine both storage consumption and execution frequency. For example, hourly incremental snapshots stored in hot storage tiers generate higher sustained costs than daily full backups archived in cold tiers. These trade-offs must be explicitly modeled using snapshot frequency multipliers applied across a tiered storage class structure, where pricing is calculated as (per-GB/month) × (retention duration) × (snapshot count) × (version depth).
Storage architecture choices impose further cost implications: multi-region replication and cross-border data synchronization trigger egress charges and region-specific replication fees. The use of immutable WORM-enabled storage, often required for regulatory compliance, introduces archive storage classes with significantly higher per-GB costs than standard object layers. In regulated industries, these configurations are mandatory and represent fixed cost baselines rather than optional add-ons.
Automation workflows contribute to operational cost through API invocations and scheduled task executions. Frequent auto-validation cycles, restore simulations, and failover drills consume compute resources and trigger platform-specific automation charges. Higher SLA performance tiers, such as low-latency RTO guarantees, often include surcharges tied to restoring provisioning faster and reserved bandwidth, adding another dimension to cost modeling.
Compliance mandates further extend cost exposure by requiring longer retention windows, tamper-proof storage, and regional data segregation. For instance, HIPAA or SOX compliance may require 7–10 years of immutable backup retention, audit log preservation, and repeatable restore validation. These requirements increase both the volume and class of storage consumed, expanding the scope of monthly billable resources.
Restore operations also generate per-event costs. Each restore may incur data read charges, bandwidth consumption, and triggered automation workflows. Even test restores add to the total cost profile through infrastructure usage and API executions. Systems with high backup-to-restore ratios must account for both active recovery events and policy-driven simulations in their cost projections.



Contact
Don't like forms?
Shoot us an email at [email protected]
